


Reflecting on the Crowdstrike faulty update that stopped the world
The most comprehensive overview of the biggest global IT outage the world ever experienced

Exactly one week ago, Crowdstrike released a faulty update for their products that caused a major global outage. In this article, I will explore what happened since then, and what most likely will happen next.
On July 19, 2024 at 04:09 UTC, as part of ongoing operations, CrowdStrike released a sensor configuration update to Windows systems. Sensor configuration updates are an ongoing part of the protection mechanisms of the Falcon platform. This configuration update triggered a logic error resulting in a system crash and blue screen (BSOD) on impacted systems.
The sensor configuration update that caused the system crash was remediated on Friday, July 19, 2024 05:27 UTC.
This issue is not the result of or related to a cyberattack.
According to Microsoft, the incident affected 8.5 million devices. Judging by the impact this situation had all around the world, the number does feel higher, and other estimates have put it several orders of magnitude higher.
The problem cause by Crowdstrike update could not be solved remotely so manual access to the “bricked” devices was necessary. Companies and individuals all around the world were affected with real life consequences, like cancelled flights, healthcare treatments halted and banks not able to serve their customers.
The real life consequences
When there was still not a clear culprit behind the outages, during the first hours of chaos, videos and social media posts started to surface showing the real life consequences of this incident.
Passengers stuck on airports were confused and angry as airline staff wasn’t able to handle the situation to their satisfaction. In some cases, the treatment they received was outrageous, with people not getting full refunds for their cancelled flight.
That was not all: there have been reports of healthcare facilities needing to halt treatments, banks not able to serve their customers whom couldn’t withdraw money or make online transactions, and more.
Shockingly, once it was known that a Crowdstrike issue was behind the problems, there have been reports of the company’s employees being harassed at their houses, at least in Australia. In a video published on TikTok, for instance, a journalist was seen ringing at the door of a local leader of the Austin-based cybersecurity company.
Continuing with Australia, the early estimations of the economic damage caused by this incident put the damage bill above USD 1 billion - or 27 % of Crowdstrike’s Annual Recurring Revenue as of April 30, 2024, depending how you want to express it.
Cybercriminals took immediate notice
It didn’t take long until reports of phishing and other scams started to appear using the incident as a way of target companies and individuals.
Lookalike domains to crowdstrike.com were quickly setup by cybercriminals, where “solutions” to the problem were offered, among other techniques that cybercriminals used to profit from the situation.
This is something common every time a known organization experiences any sort of incident or there is a major story breaking, situations that are used regularly for phishing and fake websites.
Among the different types of scams, there have been several accounts of phone calls to affected businesses and institutions from “Crowdstrike support”, offering software or tools - for a price - to automate the recovery process, something that was not possible at the time.
It’s unknown how many individuals and businesses fell victim to these attacks, but there’s no doubt some did.
The ambulance chasers
Cybercriminals weren’t the only ones trying to profit from the incident. Some Crowdstrike’s competitors showed their true colours during these days too.
While some competitors called for a “truth”, highlighting this was a moment to focus on how to help the affected customers instead of punching Crowdstrike while down.
Others went full on to position themselves as an alternative that customers could trust would never cause this type of problems, which cause causing many cybersecurity practitioners to react and call them out as ambulance chasers.
Some cybersecurity vendors’ reactions were in a sort of “middle ground”, calling out the concentration of the market in a few vendors as one of the causes of these incidents, and underlining how a more “diverse" security market would minimize the effect of this type of events.
The root cause
Crowdstrike released a Preliminary Incident Review (PIR) on July 24th, 5 days after the incident. Until then, the information provided described the technical aspects of the issue only superficially, which sparked a lot of speculation about how this faulty update could have reached millions of devices around the world.
According to the PIR, the cause of the issue was the release of a "content configuration update” that had the objective of "gathering telemetry on possible novel threat techniques”, a regular operation the Falcon Platform.
This was done through a type of update that Crowdstrike calls Rapid Response Content, which extends the capabilities of the regular Sensor Content maintenance. The problematic update included two “Template Instances” that passed the company testing process despite containing problematic content data due to a bug in their “Content Validator”.
The information provided by the PIR confirms that the issue was caused by an exception provoked by an out-of-bounds memory read, which then caused the Blue Screen of Death (BSOD) as it wasn’t “gracefully handled”.
When reading the incident report provided by Crowdstrike is clear that this incident is a result of a complex failure where several things went wrong and the testing process wasn’t prepared for them.
The report confirms some of the early speculation and analysis by different sources. Moreover, it includes several improvements the company expects to implement in order to prevent this type of issues in the future.
The promised enhancements confirm that the current update process wasn’t comprehensive enough, and considers changes in many steps, from the testing performed locally by developers to how their sensors perform validation checks and exceptions handling.
The PIR doesn’t provide information about how an update like this could have reached so many devices so quickly, when best practices call for releases in batches in order to prevent potential issues.
Considering that there were early warnings that potential problems could arise in the Falcon Platform, due to similar issues that were experienced by Crowdstrike’s customers in other operating systems, a key question remains: why this process improvements weren’t in place already?
CrowdStrike’s response
Crisis, especially global ones, require swift reactions and straightforward communication, and that’s exactly what Crowdstrike has been doing. When you literally stop the world, you can’t hide.
Besides setting up a dedicated online hub that gas been regularly updated with the latest information for their customers, partners and the community at large, George Kurtz, the company CEO, has been publicly addressing concerns in multiple media - like CNBC and The Today Show - and platforms - like Linkedin.
Crowdstrike’s response didn’t end there. Apologies were given, not only their executive leader. Other key people has been part of the company’s crisis management, like Shawn Henry, their Chief Security Officer, widely respected in the cybersecurity community, and the company’s President, Michael Sentonas, who openly said: “Let me be clear, we got this update wrong, we will learn from this and will be better”
The communication had multiple layers: addressing concerns about a potential cyberattack, providing details of the issue, guidance on how to solve it, collaborating with other industry leaders - like Microsoft - to support their customers, and more.
Crowdstrike even provided ways to customers to automatically fix the issue since July 22nd, at least in some scenarios.
Taking the story on their own hands, Crowdstrike showed the type of leadership that is required to handle a situation of this magnitude. This was well-received by a large number of their customers, whom took it to their own social media accounts to support the company during this difficult times for them and everyone affected.
Finally, the release of the Preliminary Incident Review mentioned above shows that the company is delivering what they promised since their crisis response started.
Some customers showed their support, publishing messages - on LinkedIn and other social media platforms - about how satisfied they were with how the company handled the crisis communication. However, judging by the comments, the sentiment is mixed, with many other clients expressing their frustration and anger as well.
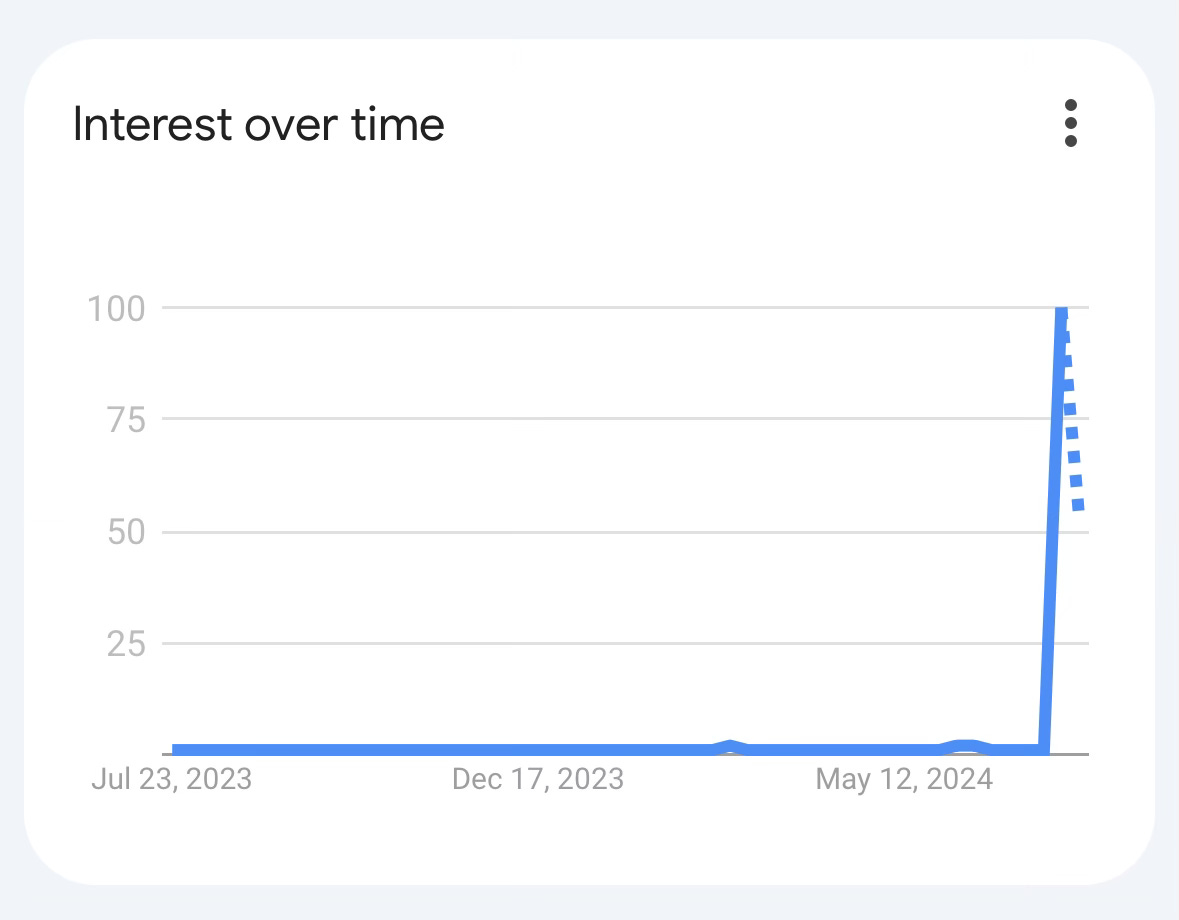
(Crowdstrike’s Web Search interest over the past 12 months - Google Trends)
Wait a minute! Updates, you say?
Before we continue, let’s take a look again at what caused this worldwide incident: an update. For those that, like me, have been in this industry for a long time, the fact that this is the source of this situation is extremely interesting, to say the least.
Crowdstrike has been positioning themselves against the so-called “Legacy AVs” since the beginning of their very successful journey. One of their claims has always been that the problem with their competitors is that they needed constant updates of their “signatures" to be effective and that didn’t work anymore, implying they didn’t need to do that thanks to their AI-based approach.
Now, that their EDR is requiring updates “several times a day” to be effective or they’d be a “bit worthless” as a Linkedin user put it, it shows the hypocrisy of their original marketing messaging. Some would say that karma finally paid them a visit, considering the need for updating is what caused this never-seen-before incident.
When everything calms down and things go back to normal, Crowdstrike's leadership could well re-consider the veracity and appropriateness of their claims and start to focus on communicating their strengths - that they have many - rather than the imaginary weaknesses of others.
Let’s go back to the mother of all outages…
Culprits everywhere
While it’s undeniable that Crowdstrike bears all responsibility for the faulty update that caused this global IT outage - pending the above-mentioned Root Cause Analysis - some questions demand answers.
What has been the role of Crowdstrike’s customers and of Microsoft in all of this?
Several cybersecurity practitioners have been asking themselves and the community how can it be that the users of the company’s products are letting updates go to production systems without appropriate testing.
We are talking about computers that handle air transportation, financial transactions, healthcare treatments and many other critical functions, and somehow, they are set to automatically update their security solution which is, to put it bluntly, a very poor practice.
However, it’s unclear what the customers could have done to prevent these issues. Crowdstrike seems to be releasing updates several times per day, and it’s unclear if the Falcon Platform allows for the delay or prior test of the Rapid Response Content that caused the BSOD.
In retrospective, the economic losses caused by this incident show the relevance of a better approach to updates management by both Crowdstrike and their customers, whom should have make it clear to the company that they needed the resources, means and functionality to have a better governance over this process.
Besides that, let’s also consider the role of Microsoft in all of this for a moment. Does it make sense that a malformed file, loaded by a 3rd-party application driver, can crash the whole operating system?
Several respected experts mentioned that this is, in a way, a safety measure, as a malware could crash a security product, and an infected system shouldn’t be running. Now, it makes sense to find ways to preven that, but cause a BSOD to avoid that situation?
Among others, Kurt Natvig, an experienced and highly respected malware researcher, took to Linkedin to discuss different ways that the Early Antivirus Malware Launcher safety measures could be made compatible with avoiding the Windows’ behaviour that was triggered by the faulty update.
Interestingly enough, Microsoft’s Chief Communication Officer took to X (formerly Twitter), to blame the European Commission for their inability to close the operating system in a way that this type of incidents wouldn’t happen.
Crowdstrike products are definitely responsible for triggering this global chaos, but there have been several other elements that could have prevented this from happening, and they didn’t.
Crowdstrike’s Market Leadership
A few days before the incident, Crowdstrike was proudly announcing that 99 % of their customers, at least those reviewing their solutions on Gartner Peer Insights, were willing to recommend their endpoint protection platform.
Moreover, Crowdstrike is the Leader of the Endpoint Protection Platforms market according to the latest Gartner Magic Quadrant. How can it be that with such market position they got themselves into this situation? Shouldn't proper release processes be a pre-requisite for a market leader?
Nowadays, the Gartner Magic Quadrant has an area connected to Operations that would be the only one that could really be considered affected by this incident. It has a Medium weight, which wouldn’t change the final result much at the moment, though.
From the Gartner Magic Quadrant
Operations: This criterion addresses a vendor’s ability to meet goals and commitments, including the quality of the organizational structure, skills, experiences, programs, systems and other vehicles that enable the organization to operate effectively and efficiently. Evaluation factors include resources dedicated to EPP product R&D and threat research, organizational structure, certifications and processes, and end-user training programs.
Maybe Gartner - and other analyst firms that have been considering Crowdstrike a leader for some time - should consider giving the above a bit more weight, when we take into account what is the impact we are seeing for a faulty release process, which is the most likely culprit of this situation.
Moreoever, one of the usual steps in previous Magic Quadrant editions is a questionnaire that vendors need to fill which includes hundreds of different topics, and another is a demo of certain use cases selected by the analysts in charge of the report.
After this incident, I wonder if the update release processes of the evaluated companies as well as the functionality required to be able to choose manual or delayed updates instead of automatic will be a key part of the next version of this Gartner research…
The backlash
Despite all their efforts post-incident and besides the ambulance chasing of their competitors, Crowdstrike has been experiencing a large amount of criticism from different fronts.
Many customers have jumped to LinkedIn and other social networks to post messages and videos to show their disatisfaction with the consequences of Crowdstrike’s faulty update.
Some of those clients have a very high profile, like Elon Musk, who informed that his companies have deleted Crowdstrike from all their systems.
The impact this incident had on millions of people around the world, with losses estimated on the billions of dollars, clearly justifies the anger and frustration of those affected, considering Crowdstrike is among the most expensive products in the market.
The consequences for Crowdstrike will not end anytime soon, considering their CEO has been called to testify in front of the US Congress about the company’s role in the global IT outage.
Some have highlighted that if some European Union regulations - like DORA - would be already in place, the backlash and consequences for Crowdstrike - and the company’s customers - would have been even larger.
The unsung heroes received the praise they deserve
There is a group of people that received praise and recognition from everyone involved: the IT and security teams that needed to get all hands on deck and work through weekends and nights to get critical systems around the world back online.
Considering that there have not been any other way than a manual fix for several days, and that some configurations required additional work. For example, the systems with Microsoft Bitlocker without recovery keys were a big headache for everyone until a tool was released.
IT teams scrambled everywhere, from airports to enterprises of all sizes, to do everything they could to implement the known and experimental fixes as they became available.
Some showed a high degree of ingenuity and creativity, like the teams at Grant Thornton Australia, who came up with an innovative approach using a barcode scanner, speeding up the process of recovering affected devices.

These usually unsung heroes that keep the global IT infrastructure running every hour of every day faced the most widespread challenge ever and received - and still receive - the recognition they deserve.
What happens next?
While the economic losses of this incident are only starting to be estimated, there are many things that will yet happen and will take some time to unravel.
Crowdstrike’s stock price suffered a drop of more than 20 % since the incident, while it’s still not known what will be the real impact on the company’s financial performance. Questions about the legal consequences they will face, the refunds that they might need to extend to their customers, and if their insurance - and their client’s insurance - will cover for the monetary impact of this outage are still un-answered.
Considering the billions of dollars in damages and losses, several times higher than the annual revenue of the company, this could lead to extreme situations, and legal experts are already pondering the potential class actions against Crowdstrike, with the word “bankruptcy" floating in the air.
How customers react from now on, staying with Falcon Platform or not, will be key, and some experts, like Richard Stiennon, believe that the company will not be truly affected.
Interestingly, Asia has been the least affected region by the outage, as Crowdstrike isn’t as popular there as in the Western world. Would this incident strengthen a move to look even more into non-Western security solutions in that continent?
There are several concerns that have been appearing, like the consolidation of security products and operating systems that enabled this outage, as well as the expectations that CIOs will re-think their cloud strategies.
Not only that, some experts are preoccupied with thoughts about how this will affect the behaviour of users regarding automatic and regular updates.
That’s exactly what it was worrying now: what are going to be the consequences for the technology and security world in general. Will the trust in the whole cybersecurity industry diminish? Will new regulations be in place to ensure this type of incident doesn’t happen again?
In a world where a handful of technology vendors control the majority of the market, where 62 % of the external attack surface is concentrated in 15 companies, there’s clearly a need for more focus in preventing incidents, and invest more in resilience.
The way that Crowdstrike continues to respond to the incident, as well as how it’s judged by customers, their partners and governments will determine not only the future of the company and its products, but potentially change more than that.
The next weeks - and potentially months - will start to show if this is an opportunity for change, for learning from a complex failure that affected large parts of the world, or things will just return to the mean and continue like if nothing happens.
What cannot be denied is that answers are still needed, and there’s going to be a before and after marked by the biggest global IT outage the world have experienced so far.